概要
畳み込み層のあるDNNモデルは人間並みに画像の分類をできるようになりましたが、未知の分類対象に対して誤った分類して、信頼度が高いと判定してしまいます。(ホワイトノイズの画像ライオンと分類し、その信頼度が99%と判定するなど)

先行研究との比較
False Positiveが多いのはAlexNetなので、AlexNetで学習済みのモデルを使います。(学習データはILSVRC 2012 ImageNet dataset)Lenetでもテストしています。(学習データはMNIST)今回検証するための画像はevolutionary algorithms(EAs)で作っています。

多クラス分類に対してはMAP-Elitesの方が良い結果が出ているのでこちらを利用しています。
The MAP-Elites algorithm searches in a high-dimensional space to find the highest-performing solution at each point in a low-dimensional feature space, where the user gets to choose dimensions of variation of interest that define the low dimensional space.
技術や手法の特徴
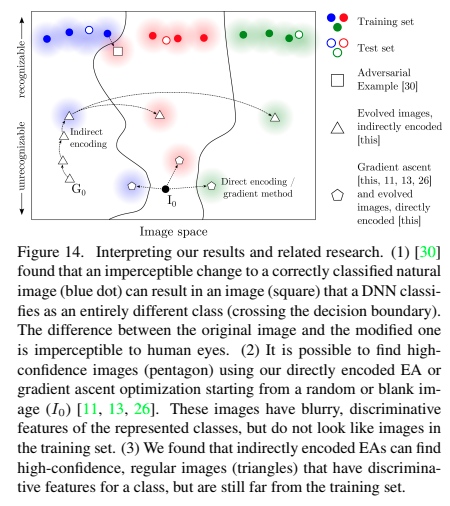
direct encodingとindirect encodingの2種類のencodingの方法で画像は生成しています。
direct encodingは、10%の確率でノイズを入れます。pixelに対して0~255の間で一様分布のノイズです。indirect encodingでは、画像の情報を左右対称や、繰り返しなどの加工しています。ここではcompositional pattern-producing network(CPPN)を使っています。(元画像に似せたノイズが作れるみたいです。)
CPPNで加工すればこうなります。

検証方法
MNIST

MNISTで学習したDNNではfig4(direct encoding)を99%の信頼度で数字と判定しました。ただのノイズではなくちょっと原型が残っているindirect encodingも試したが同じ結果となりました。

ImageNet
direct encodingでは信頼度のmedianは21.59%でした。一方で、fig1の画像を使った場合、信頼度が99%以上でした。

indirect encodingで5000枚使った場合の信頼度のmedianは88.11%となりました。結果が悪いところは犬と猫のカテゴリーで、理由はImageNetに犬と猫のカテゴリーが多すぎることが問題であるとしています。(犬ならチワワとか柴犬とかいろんな種類があります)

fig2のevolutionary algorithmを5回適応した画像です。なんとなく原型残っています。

CPPN-encodingで新しい画像を作って規則的にリピートを入れています。これでもクラス分類されて、しかも信頼度は高い結果となってしまっています。

DNN
ここで気になってくるのが、1つのDNNを騙すことができたら他のDNNも騙されるのかということであります。DNNをMNISTやImageNetをデータセットで学習すると、騙しの画像だとわからずに適当なclassに分類してしまいます。しかし、一度学習した後に、騙しの画像を学習すると、騙しの画像classに分類できるようになるのでないかという検証をしています。
MNISTではうまくいきませんでした。

ImageNetではうまく分類されました。DNNの更新は1度だけです。(DNN1とDNN2)

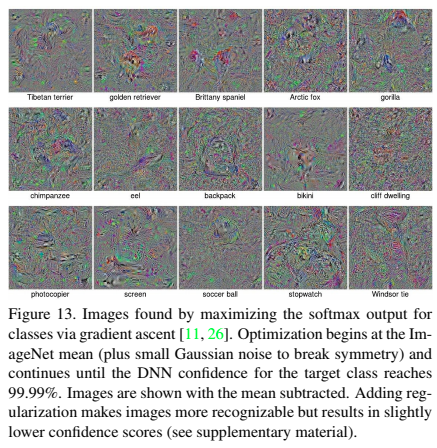
gradient ascentを使って加工した画像で試してみます。そうすると、何かわからない画像でも高い信頼度で分類してしまうことがわかりました。
議論
加工前の画像と似ている加工後の画像に対する分類はうまくいきましたが、全く認識できない画像に対しては分類がうまくいきませんでした(間違ってしまった)。