元論文はこちらからダウンロードしてください。
概要
コンクリートの欠損をdeep learningを使って見分けます。写真を撮っている状況/環境が違ってもコンクリートの欠損を検出可能。
先行研究との比較
従来の研究では光の当たり具合などの外部環境により検出に問題がありましたが、CNNを使うことで改善されました。以前はエッジ検出(sobel or canny)などでしたが、光の加減やdistortionに弱く、良い精度が出ていませんでした。
多くの物体の欠損検出の研究でimage processing techniqueとmachine learning algorithmが使われています。その中でcnnが一番良い結果を残してきています。しかし、現在のCNNやNNを使った検出では多くのラベリングされた画像と計算コストを必要とすることが問題点とされています。
この研究の検出目標:
- cracks of concrete(コンクリートのひび割れ)
- delamination, voids, spalling, and corrosion of concrete and steel members(コンクリートと鋼材の層間剥離、欠け、破砕、腐食)
過去の検出方法との比較。



技術や手法の特徴
画像
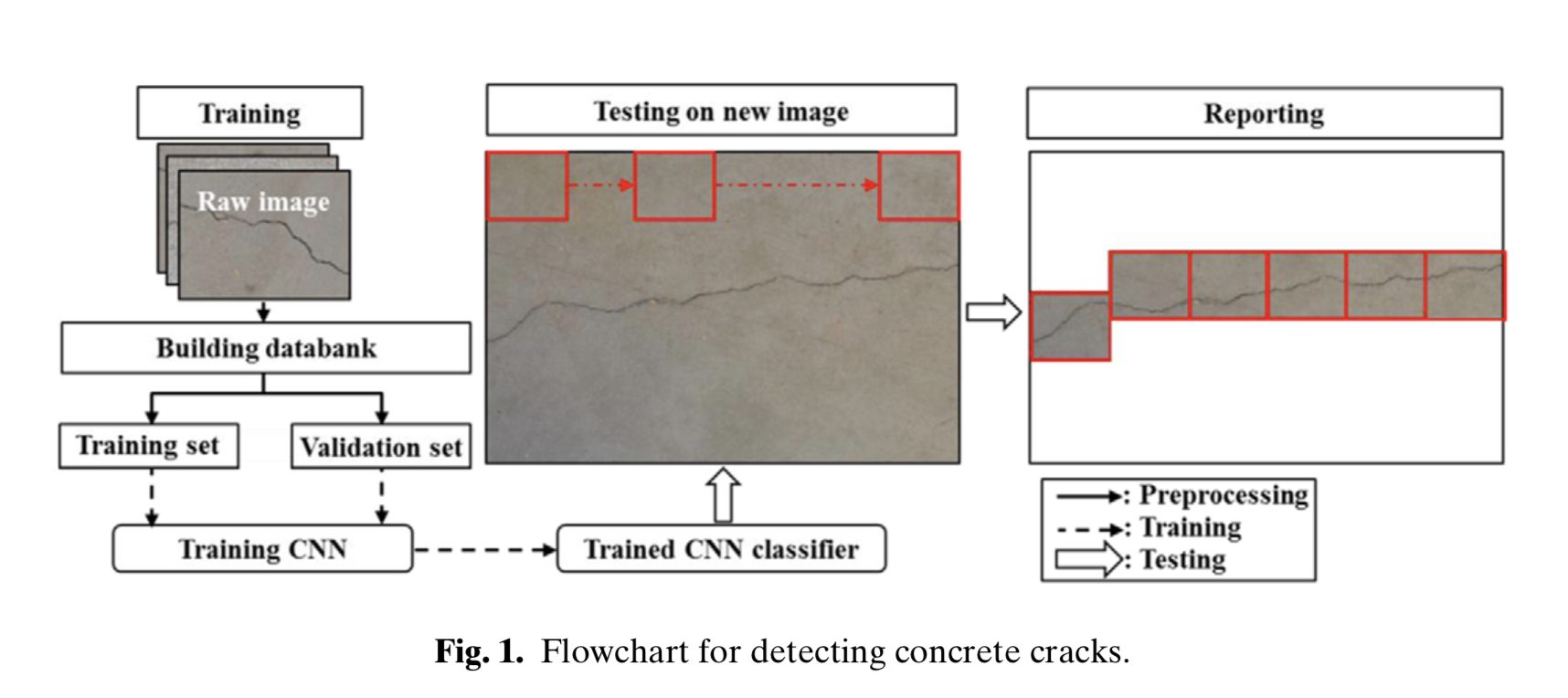
322枚の画像
trainingとvalidationに277枚(4928×3264)、testに55枚(5888×3584)
trainingとvalidationの画像は256×256にcropして手作業でanotationをつける。
(検出に対応させる画像よりも小さい画像である必要があるためcropする)
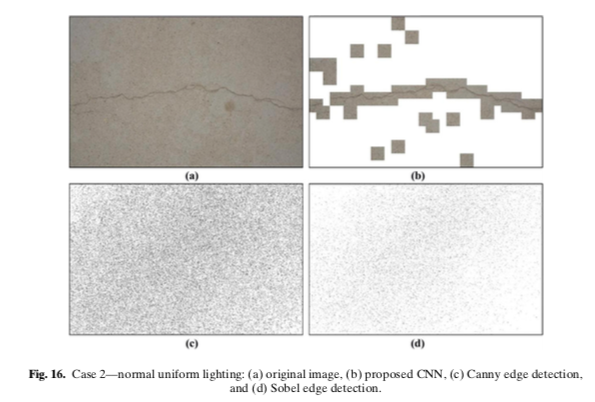
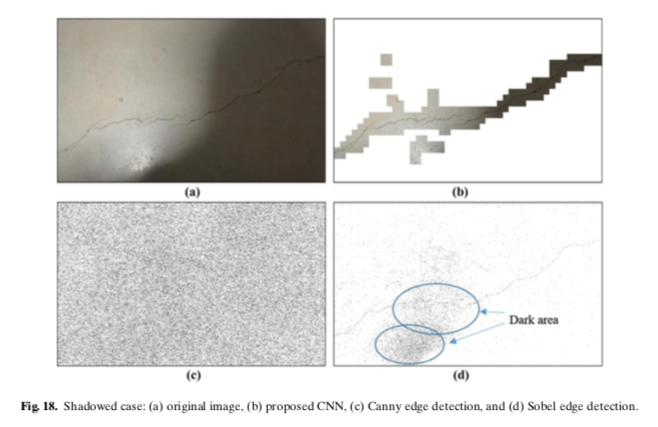
fig7の画像はうまく検出できるが、fig8の画像は検出が難しいようです。


カメラはDSLR camera (Nikon D5200)を使い光の当たり具合を変えて撮影しています。
CNN
MatConvNet (Vedaldi and Lenc, 2015)を使っています。
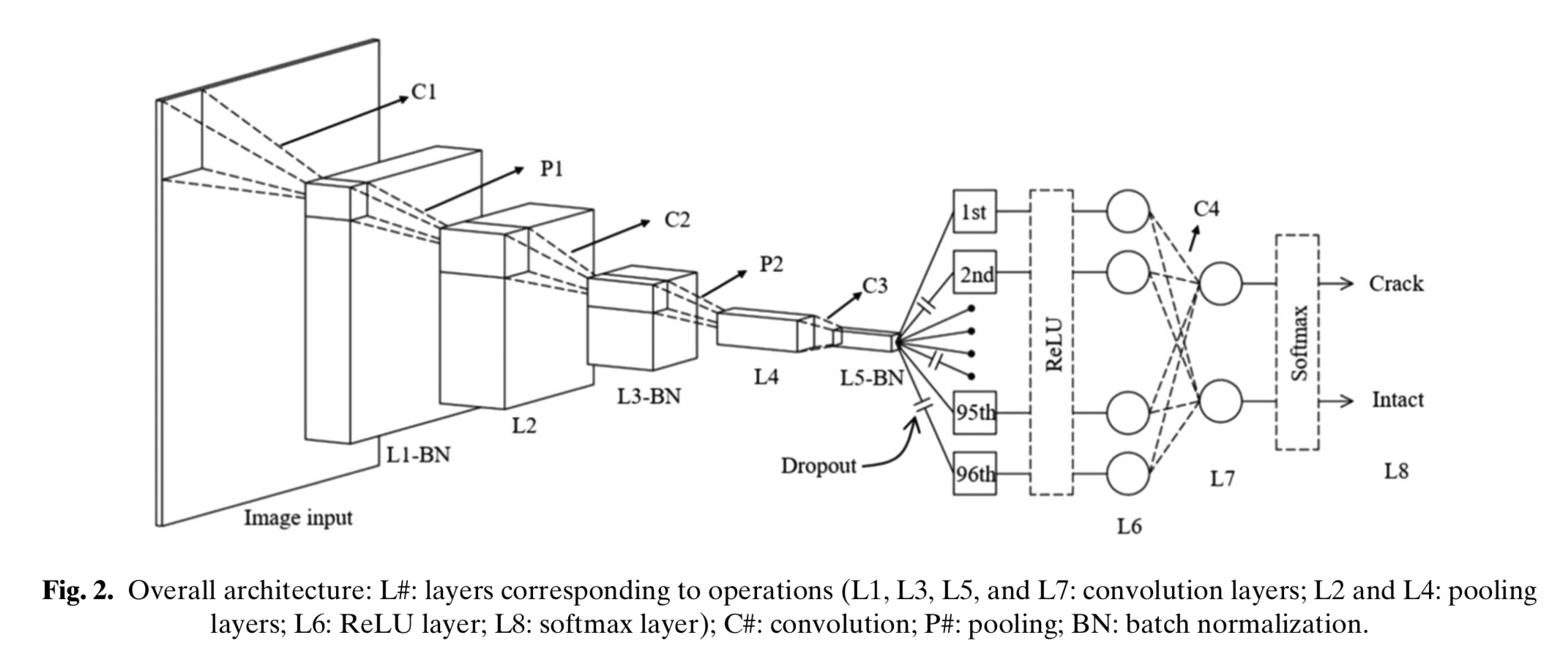

ミニバッチサイズは100、小さいlearning rateからはじめて減少させます(Wilson and Martinez, 2001)。
重み減衰(Weight decay)は0.0001、SGDの方向や距離(momentum)は0.9。
strideはC1からC3、P1からP2までは2、C4は1。
ReLUの前のドロップアウトレートは0.5。
欠損が画像の端にある場合うまく検出できないことを考慮して、testデータに対するsliding windowsは2回に分けて行う。
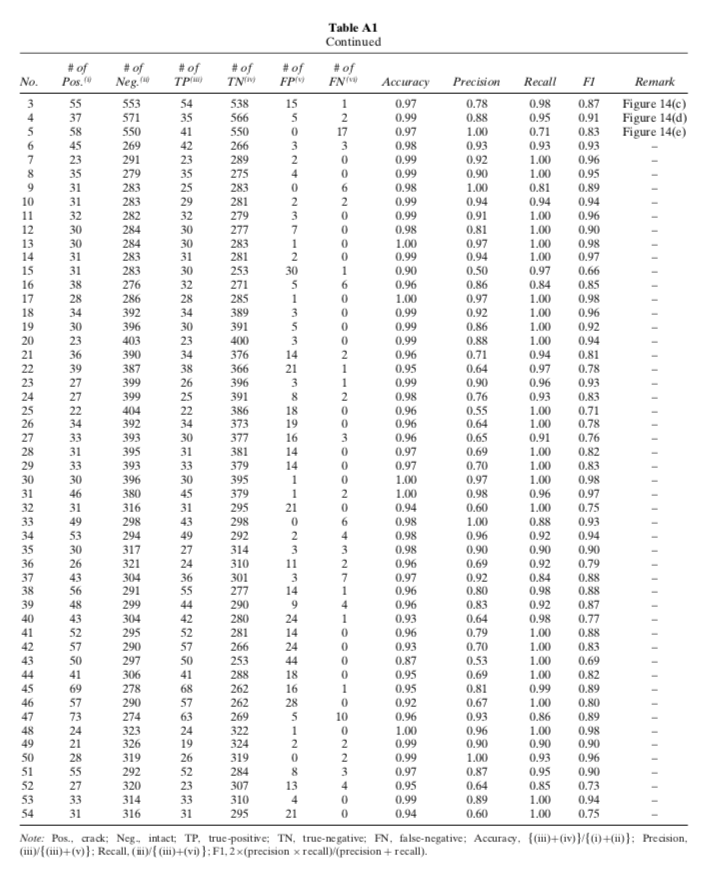
検証方法
validationデータの結果。

実際はこのような感じで検出されます。


高精度。